Thread by Hrishi Olickel
- Tweet
- Apr 24, 2023
- #ComputerProgramming #DataScience
Thread
Can a new transformer architecture with 2 million 🚀 tokens fix the token window problem?
Or are there no free lunches? What do we gain, what do we give up?
New paper from @MikhailBurtsev, Aydar Bulatov and @yurakuratov
Let's break it down👇
arxiv.org/abs/2304.11062
Or are there no free lunches? What do we gain, what do we give up?
New paper from @MikhailBurtsev, Aydar Bulatov and @yurakuratov
Let's break it down👇
arxiv.org/abs/2304.11062
The biggest issue with modern LLMs has been their token window. GPT-3 - 2049 to 4096. GPT-4 - 8096, 32K coming
A token is (part of a word) based on encoder vocabulary. For non-English languages, each character can be a token!
A token is (part of a word) based on encoder vocabulary. For non-English languages, each character can be a token!

The big problem with increasing token sizes (and why a lot have predicted that they won't increase by much) is Attention.
Attention is the method by which modern LLMs look at input and output, and compute which parts are important and need a look.
proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
Attention is the method by which modern LLMs look at input and output, and compute which parts are important and need a look.
proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
This was a big leap in Transformers coming from LSTMs and RNNs, in that we could now process the entire input text in a single pass. Much, much faster!
Unfortunately we trade that off in space. Attention scales quadratically, so for larger token windows we need more space.
Unfortunately we trade that off in space. Attention scales quadratically, so for larger token windows we need more space.
The new architecture is a follow on to a 2022 paper by the same authors that examines using Memory Tokens in the input to refer to previous segments.
This is similar to memory retrieval with AutoGPT, except at earlier stages in the transformer, with deeper integration.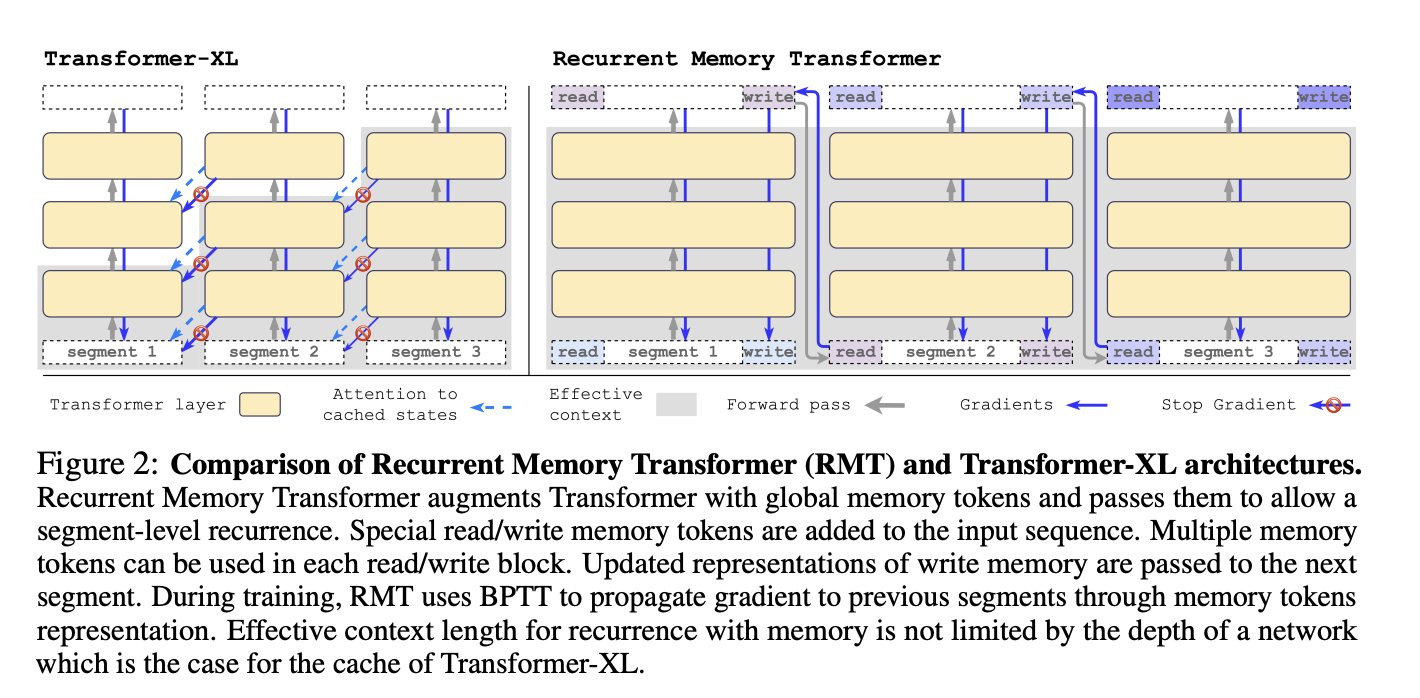
This is similar to memory retrieval with AutoGPT, except at earlier stages in the transformer, with deeper integration.

Special tokens are added to the input sequence that refer to previous segments. These are inserted into the beginning of the next segment, where information can be retrieved and appended.
At the end is another memory token for writing to memory and carrying on to the next.
At the end is another memory token for writing to memory and carrying on to the next.

Recurrent Memory Transformers in the 2022 paper showed up to four segments with minimal loss of accuracy🧠 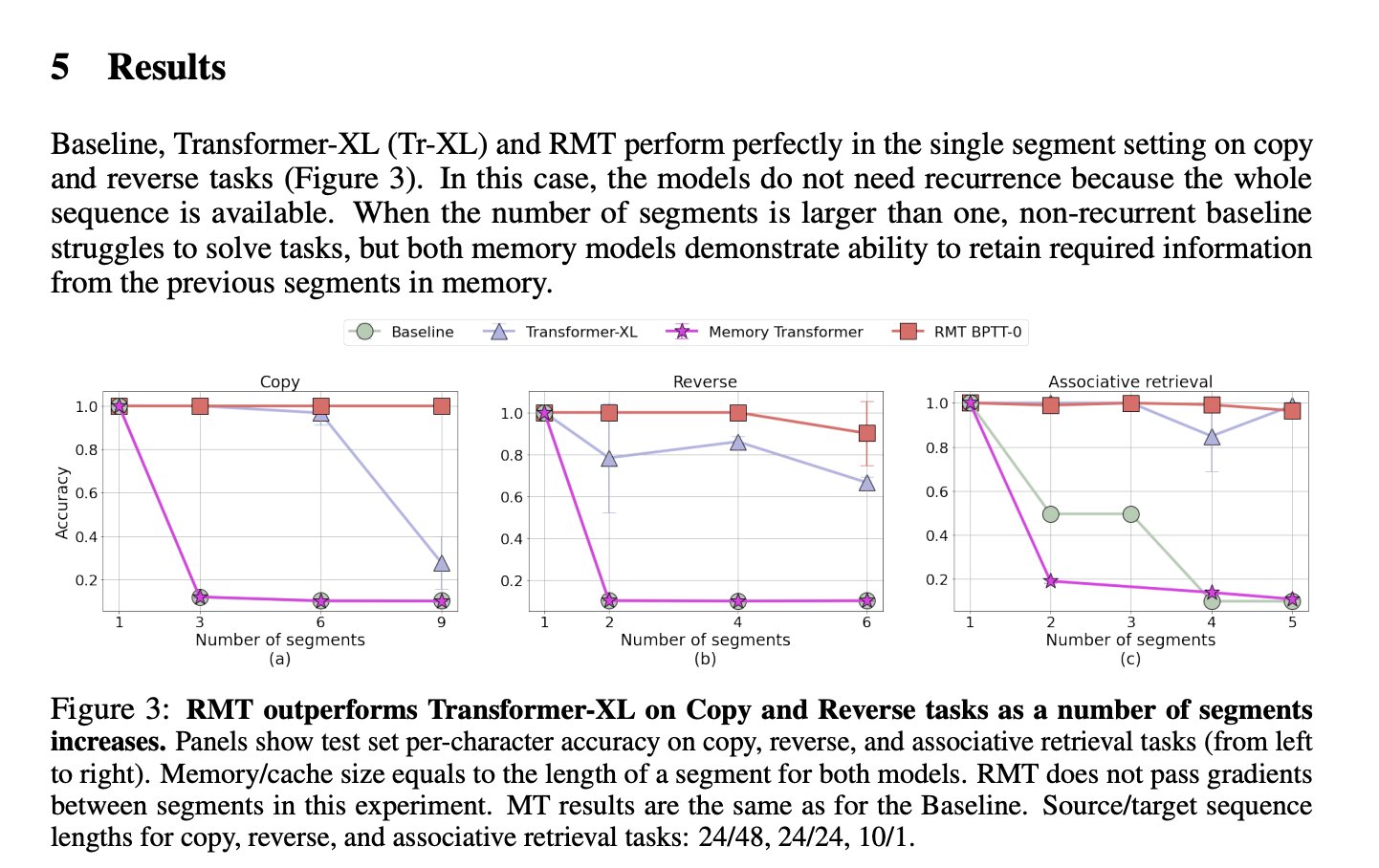

The update from 2022 is much larger tests on BERT, to see how memory demands scale.
Since they compute Attention (which scales ^2) within each segment, an increase in number of segments scales linearly - which means the limit on number of tokens might see itself being removed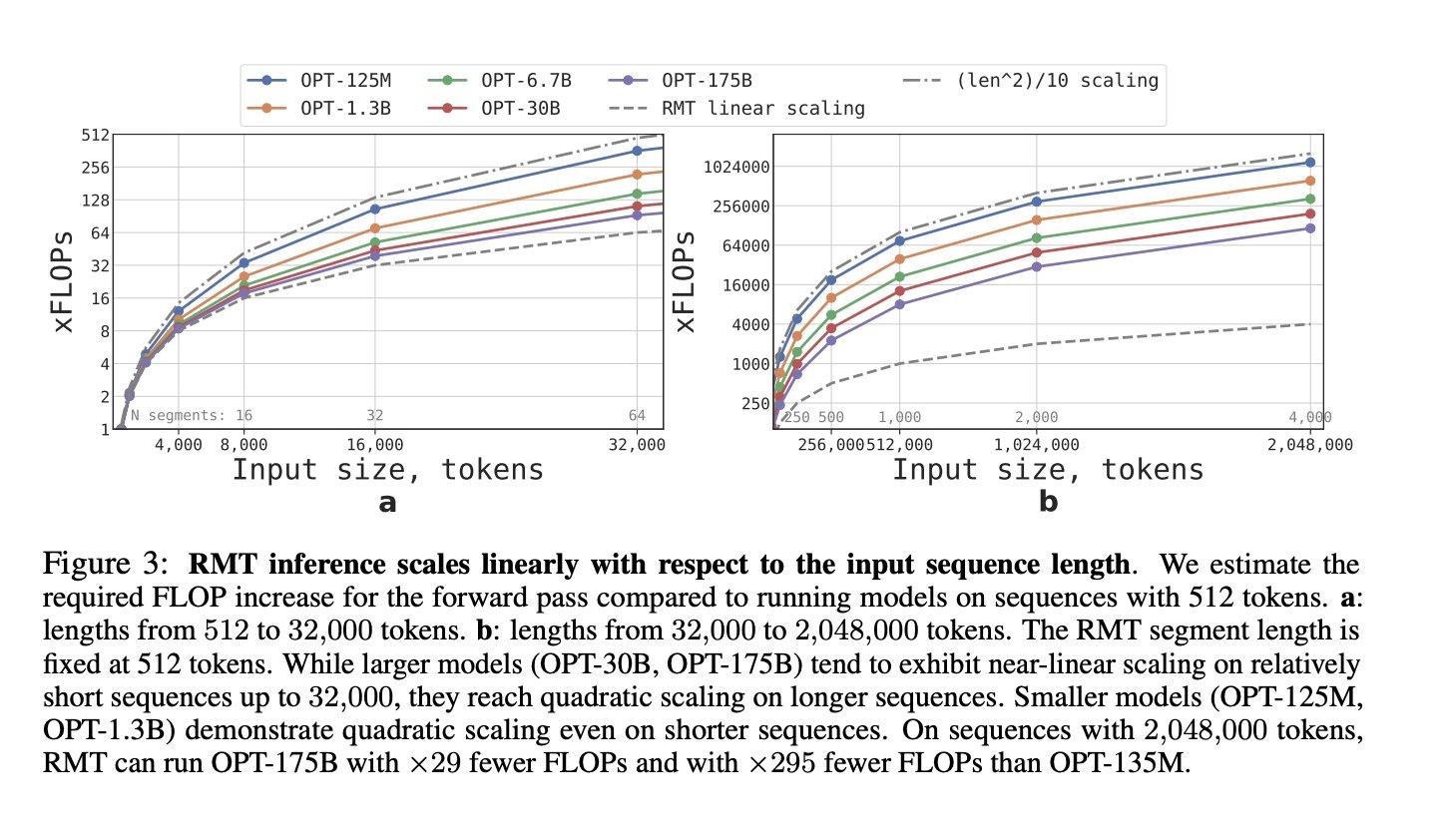
Since they compute Attention (which scales ^2) within each segment, an increase in number of segments scales linearly - which means the limit on number of tokens might see itself being removed

They tested this using 1) Facts placed in different parts of a large input sequence, with Questions that need the Facts, and 2) Reasoning questions using multiple Facts placed randomly inside a large input sequence.
The results are impressive!
The results are impressive!
Training on smaller numbers of segments showed the model getting better (almost to 100% accuracy on reasoning) as the number of segments (of input) being trained on got bigger.
The model quickly learns to place in memory the facts it would later need.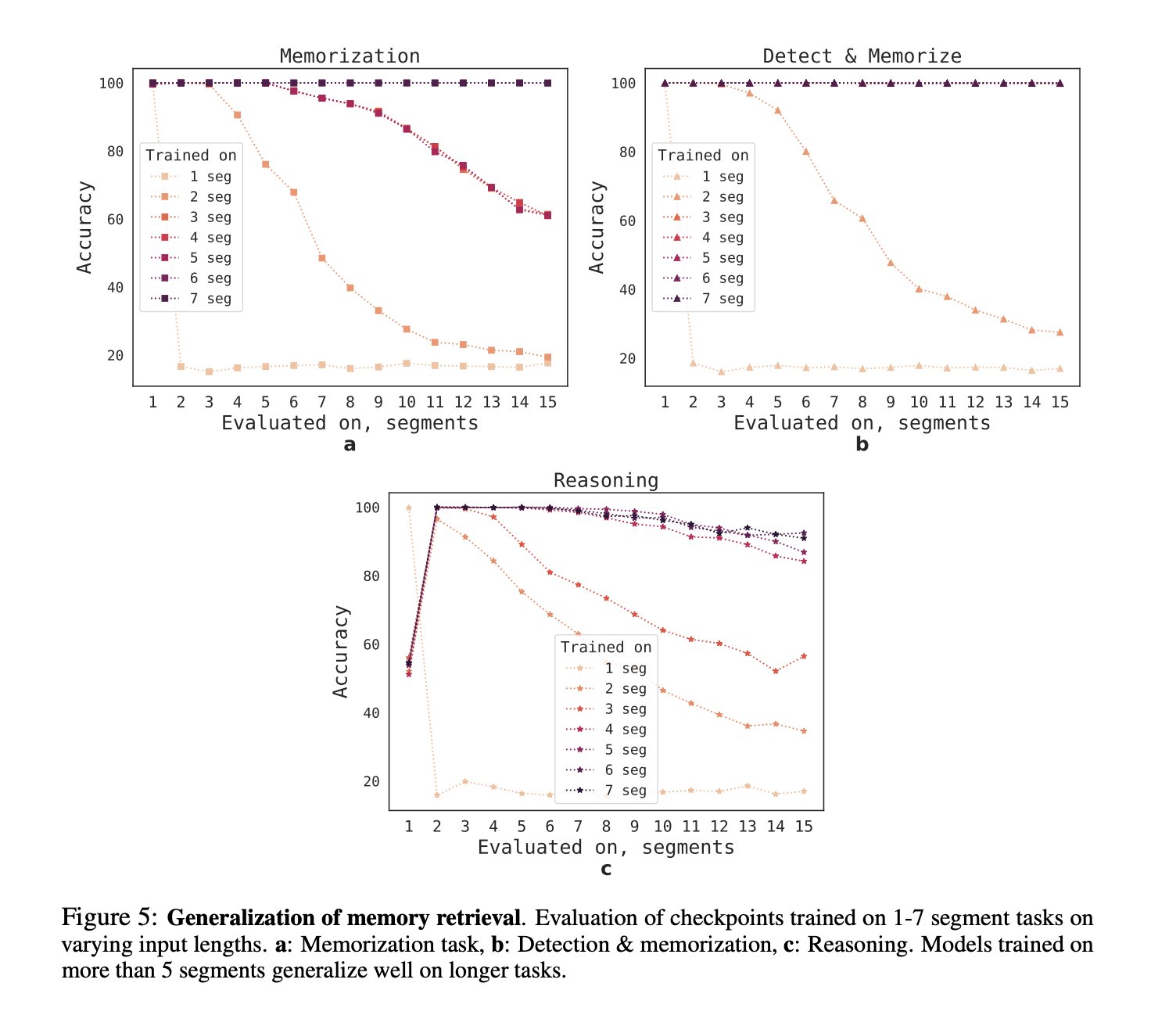
The model quickly learns to place in memory the facts it would later need.

So what does this give us?
💡This is a major leap forward in LLMs being able to process previously unheard of amounts of data - like large codebases and paper datasets.
💡It's also a general purpose architecture that works with a large number of LLMs, making application easier
💡This is a major leap forward in LLMs being able to process previously unheard of amounts of data - like large codebases and paper datasets.
💡It's also a general purpose architecture that works with a large number of LLMs, making application easier
What remains to be seen is if true intertextual reasoning is possible within the larger token windows.
The authors added natural-language text as noise, meaning that the question related to a few facts within the large text provided.
The authors added natural-language text as noise, meaning that the question related to a few facts within the large text provided.
Remains to be seen if this would work for large texts that were all relevant, and if the model could use previously learned segments to answer multiple questions that made use of almost all the data in the input sequence.
Full paper here
Full paper here
At the least, this might require a rethink of how we manage memory at the prompting stage, once this is integrated into more models.
Excited to be alive, more threads below!
Excited to be alive, more threads below!