Thread
A poorly tuned model learns too slow, overfits/underfits or worsen accuracy.
Hyper-parameter tuning by trial and error is impractical.
Techniques of Grid and Random Search turn this tedious task into an automated task, saving your time and sanity.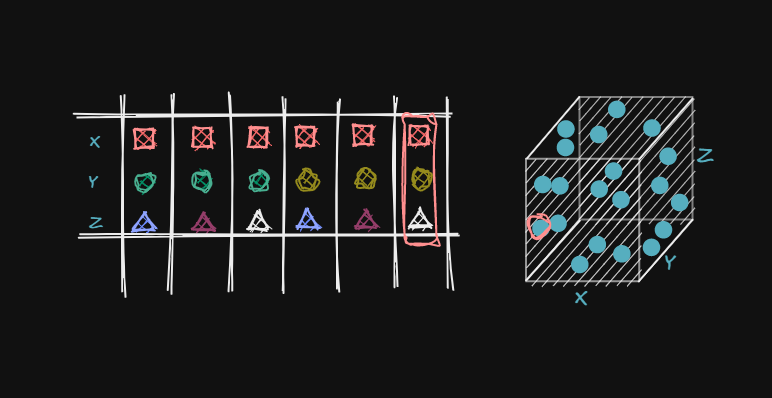
Hyper-parameter tuning by trial and error is impractical.
Techniques of Grid and Random Search turn this tedious task into an automated task, saving your time and sanity.

🔹Parameter
A parameter is what the model learns about data through training.
For ex: weights of Linear Regression..
It's NOT the same as a Hyperparameter!
A parameter is what the model learns about data through training.
For ex: weights of Linear Regression..
It's NOT the same as a Hyperparameter!
🔹Hyperparameter
Hyperparameter is a 'configuration' that is set before the model in trained.
You then evaluate different configurations by calculating 'error' like RMSE or 'Accuracy'.
Finally, you pick the best performing configuration or hyper-parameter(s).
Hyperparameter is a 'configuration' that is set before the model in trained.
You then evaluate different configurations by calculating 'error' like RMSE or 'Accuracy'.
Finally, you pick the best performing configuration or hyper-parameter(s).
🔹> 1 Hyperparameter
A model usually has many hyper-parameters.
For ex, in a Neural Network:
· number of layers
· number of neurons in a layer
· learning rate
· activation function, bath size etc.
Clearly, an automated way to pick the best values would save time.
A model usually has many hyper-parameters.
For ex, in a Neural Network:
· number of layers
· number of neurons in a layer
· learning rate
· activation function, bath size etc.
Clearly, an automated way to pick the best values would save time.
🔹Grid Search
In Grid search, all possible combinations of hyper-parameters are evaluated.
As you can imagine,
>> # of hyper-parameters ➡️ >> # of combinations.
In such a case, Grid search is computationally expensive.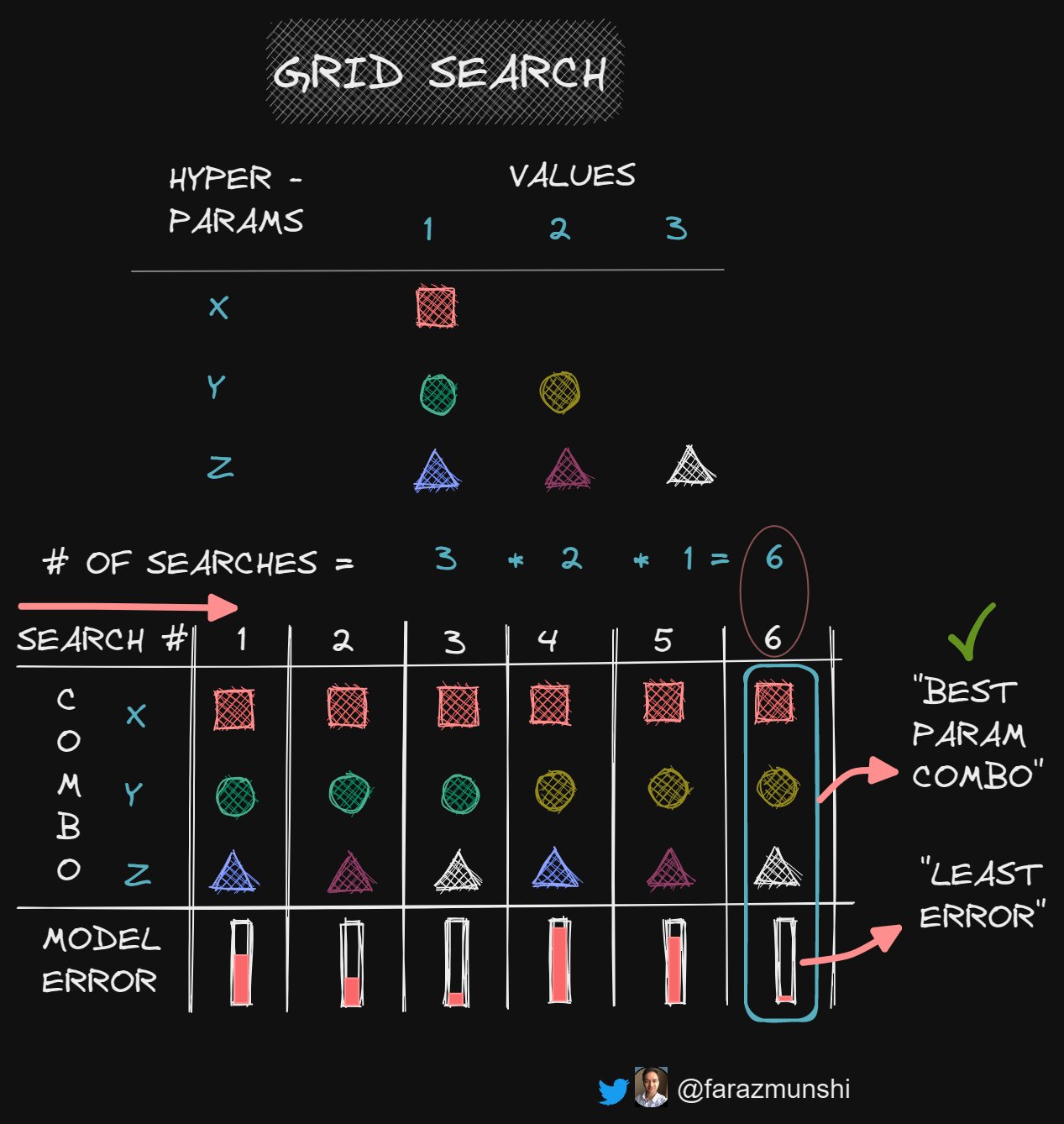
In Grid search, all possible combinations of hyper-parameters are evaluated.
As you can imagine,
>> # of hyper-parameters ➡️ >> # of combinations.
In such a case, Grid search is computationally expensive.

🔹Random Search
A Random search does a pre-defined # of searches:
· You select that # -> yielding faster results than Grid search.
Also, each dataset has different 'important' hyper-parameters:
· While Grid is exhaustive, Random prioritizes some over the rest.
A win-win!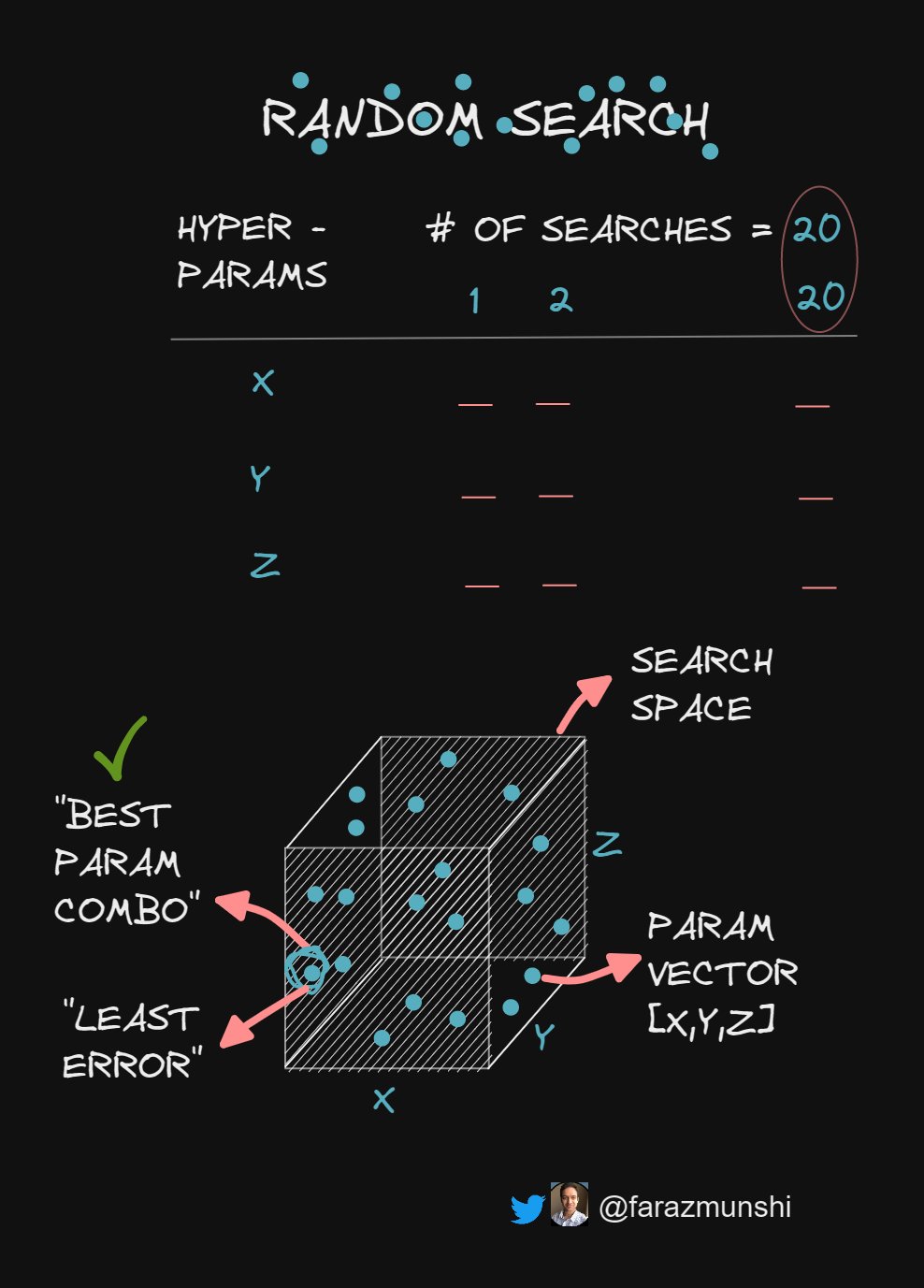
A Random search does a pre-defined # of searches:
· You select that # -> yielding faster results than Grid search.
Also, each dataset has different 'important' hyper-parameters:
· While Grid is exhaustive, Random prioritizes some over the rest.
A win-win!

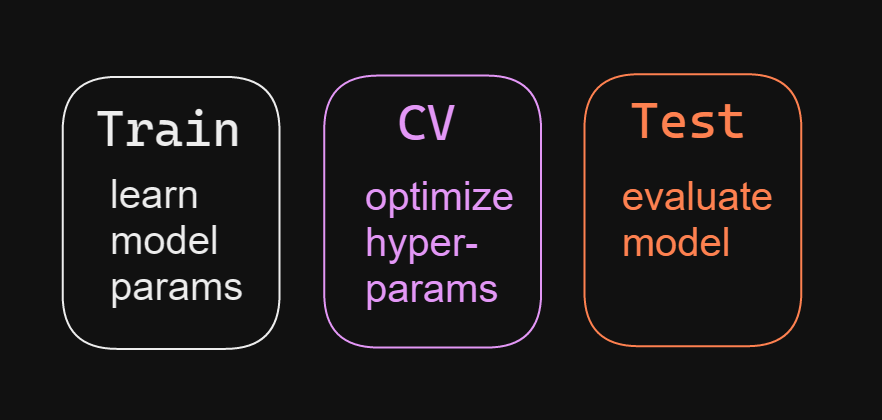
🔹Cross Validation
Hyper-parameters are always optimized on unseen data -> the Cross-validation set.
The Test set is used to evaluate the model as a whole.
Hyper-parameters are always optimized on unseen data -> the Cross-validation set.
The Test set is used to evaluate the model as a whole.
🔹Conclusion
Hyper-parameter tuning should not be like looking for a needle in a haystack.
Many libraries including sci-kit learn have easy APIs implementing both methods.
Generally:
· use random search if # of hyper-parameters is high. Else, use grid search.
Hyper-parameter tuning should not be like looking for a needle in a haystack.
Many libraries including sci-kit learn have easy APIs implementing both methods.
Generally:
· use random search if # of hyper-parameters is high. Else, use grid search.
Thank you for reading. If you like this thread, please leave a like on the 1st tweet and follow me @farazmunshi for more on ML and AI.
See you!
See you!