Thread by Fei Xia
- Tweet
- Feb 22, 2023
- #ComputerScience #ArtificialIntelligence
Thread
Text-to-image generative models, meet robotics!
We present ROSIE: Scaling RObot Learning with Semantically Imagined Experience, where we augment real robotics data with semantically imagined scenarios for downstream manipulation learning.
Website: diffusion-rosie.github.io/
🧵👇
We present ROSIE: Scaling RObot Learning with Semantically Imagined Experience, where we augment real robotics data with semantically imagined scenarios for downstream manipulation learning.
Website: diffusion-rosie.github.io/
🧵👇
It is incredibly resource consuming to collect real-world robotics data, for example it takes our robot fleet of 13 mobile manipulators 17 months to collect 130k manipulation episodes. Can we extend these data “for free” by augmenting them?
We present a system that automatically augments robot training data. All you need to tell it is a source task “place coke can into top drawer” and a target task “place coke can into cluttered top drawer”. The system outputs a few augmentation schemes, including masks and edits. 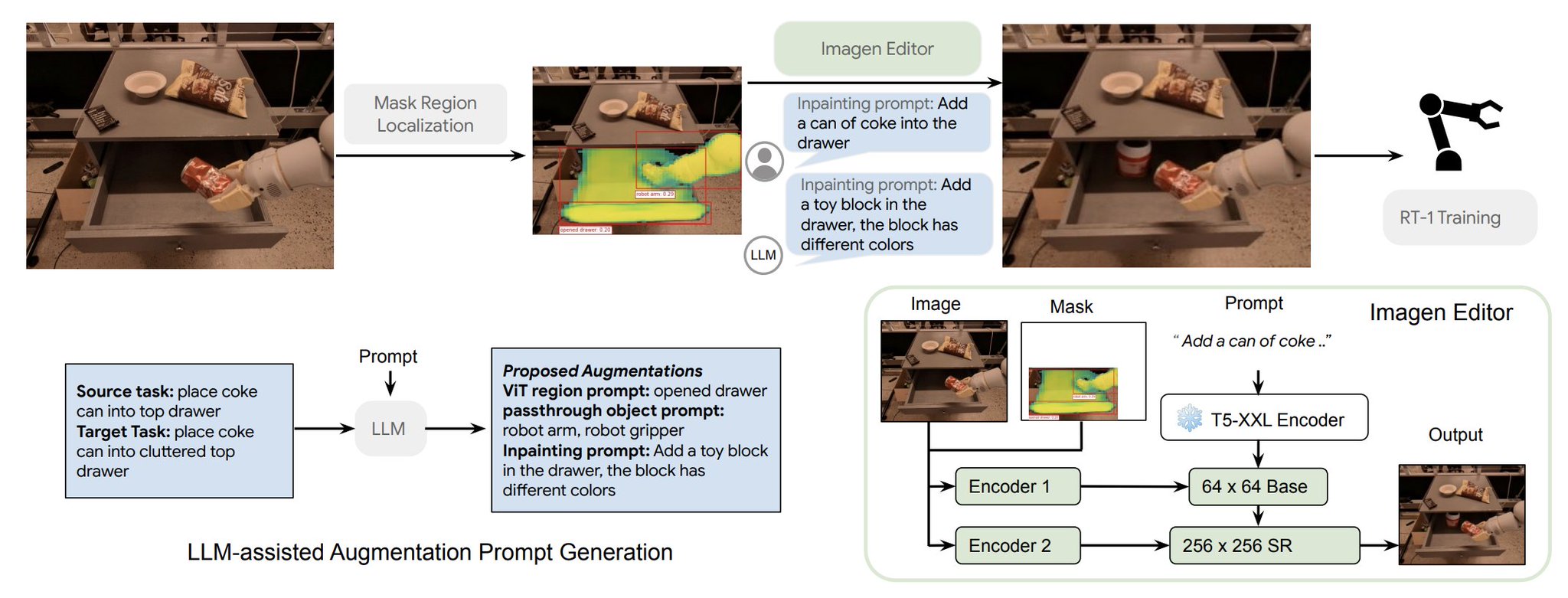

We use an open-vocabulary image segmentation model derived from OWL-ViT(arxiv.org/pdf/2205.06230.pdf) for mask generation, and Imagen-Editor (imagen.research.google/editor/) for image inpainting. We then train an RT-1 (robotics-transformer.github.io/) policy on top of the mixed data. 

A few interesting things we found along the way:
1) We can complete tasks **only seen through** diffusion models. For example, we augment “putting objects in drawer” tasks into “putting objects in sink”, by reimagining the drawer as a metal sink. The policy trained on the mixed data is able to put objects into the sink!
2) Generative data augmentation works for high-dimensional continuous action space and image frames. Our action space is the end-effector delta pose in 3D space. And the input is image frames. This is in contrast with other works in diffusion augmentation for perception.
Although our work doesn’t guarantee temporal consistency, the high-capability architecture (RT-1) is able to handle the flickering in the frames and still generalize to the real world. For example, here is the training data and real-world rollout for "picking up <color> cloth"
3) The augmentation is photorealistic and simulates rich visual nuances. Previously we have explored the knowledge and information encoded in vision-language foundation models in our work Socratic Models and Inner Monologue. This time we investigate the other side of the coin.
There is vast knowledge encoded in those diffusion models and to our surprise, there are even signs of life that they understand some physics by modeling the image formation process, see how the generated cloth has folds within the gripper pinch. Warrant further investigation
We think there are a few directions that could be further explored. It seems that diffusion models can act as a supplementary source of data to simulation. We know that we can do sim-to-real, maybe we can also do diffusion-to-real, or combine both? 

Text guidance is very important here because we can synthesize data for specific scenarios / long tail distribution of low data regimes. Essentially we get image and text alignment for free, which is fundamentally different from previous augmentation methods.
Our current method is somewhat limited by temporal consistency, we aim at incorporating video diffusion models, and masked transformers for better data augmentation.
It's also possible to incorporate ControlNet arxiv.org/abs/2302.05543 to better harness those models.
It's also possible to incorporate ControlNet arxiv.org/abs/2302.05543 to better harness those models.
The generative AI + robotics is a vibrant community. Shout out to our concurrent works GenAug and CACTI.
This work is lead by @TianheYu, in collaboration with an amazing team @xiao_ted, Austin Stone, @JonathanTompson Anthony Brohan, Su Wang, @brian_ichter and @hausman_k 🙌🙌
Visit out website diffusion-rosie.github.io/ to learn more, also checkout our interactive demo on the website. While we used Imagen-Editor for our work, the method is compatible with stable diffusion as well, we aim at open sourcing a specific version soon.